IT/SQL
[데이터 분석을 위한 SQL 레시피] 6장 13강,14강
- -
728x90
반응형
시계열에 따른 사용자의 개별적인 행동 분석하기
사용자가 최종 성과(=결과)에 도달할 때까지 어느 정도의 검토기간(=과정)이 필요한지를 알면, 대책을 세울 수 있다.

사용자 액션을 ‘시간의 경과’라는 요소와 함께 고려해서 시각화하면 행동 패턴 등을 명확하게 할 수 있다.


13-1. 사용자의 액션 간격 집계하기
💡 SQL : 날짜함수, LAG 함수, datediff
분석 : 리드 타임
🔖 리드 타임을 집계했다면 사용자의 데모그래픽 정보를 사용해 비교해보기를 바랍니다. EC사이트라면 수도권보다 지방이 이전 구매일로부터의 리드 타임이 짧거나, 연령별로 구분이 되는 등 다양한 정향이 나타날 것입니다.
리드타임
- 실제 계약까지의 기간
- <자료 청구> → <방문 예약> → <견적> → <계약>
- 리드타임 🔽 → 계약이 더 많이 일어남 → 매출 📈
같은 레코드에 있는 두 개의 날짜로 계산할 경우
숙박 시설, 음식점 등의 예약 사이트
- 예약 정보를 저장하는 레코드에
신청일과숙박일,방문일을 한꺼번에 저장한다. 숙박일-신청일= 리드타임 (datediff 함수 사용 가능)
코드 13-1. 신청일과 숙박일의 리드 타임을 계산하는 쿼리
WITH
reservation(reservation_id, register_date, visit_date, days) AS (
-- 8강 5절 참고하기
-- 임의의 레코드를 가진 유사 테이블 만들
VALUES
(1, date '2016-09-01', date '2016-10-01', 3)
, (2, date '2016-09-20', date '2016-10-01', 2)
, (3, date '2016-09-30', date '2016-11-20', 2)
, (4, date '2016-10-01', date '2017-01-03', 2)
, (5, date '2016-11-01', date '2016-12-28', 3)
)
SELECT reservation_id
, register_date
, visit_date
-- ::로 타입 변환(text를 date로 변환 후 빼기)
, visit_date::date - register_date::date AS lead_time
FROM reservation
;
여러 테이블에 있는 여러 개의 날짜로 계산할 경우
자료 청구, 예측, 예약처럼 여러 단계가 존재하는 경우 각각의 데이터가 다른 케이블에 저장되는 경우가 많음
- 테이블을
JOIN - 날짜 차이 계산
코드13-2. 각 단계에서의 리드 타임과 토탈 리드 타임을 계산하는 쿼리
WITH
requests(user_id, product_id, request_date) AS (
VALUES
('U001', '1', '2016-09-01')
, ('U001', '2', '2016-09-20')
, ('U002', '3', '2016-09-30')
, ('U003', '4', '2016-10-01')
, ('U004', '5', '2016-11-01')
)
, estimates(user_id, product_id, estimate_date) AS (
VALUES
('U001', '2', '2016-09-21')
, ('U002', '3', '2016-10-15')
, ('U003', '4', '2016-10-15')
, ('U004', '5', '2016-12-01')
)
, orders(user_id, product_id, order_date) AS (
VALUES
('U001', '2', '2016-10-01')
, ('U004', '5', '2016-12-05')
)
SELECT
r.user_id
, r.product_id
, e.estimate_date::date - r.request_date::date AS estiamte_lead_time
, o.order_date::date - e.estimate_date::date AS order_lead_time
, o.order_date::date - r.request_date::date AS total_lead_time
FROM
requests AS r
LEFT OUTER JOIN
estimates AS e
ON r.user_id = e.user_id
AND r.product_id = e.product_id
LEFT OUTER JOIN
orders AS o
ON r.user_id = o.user_id
AND r.product_id = o.product_id
;
같은 테이블의 다른 레코드에 있는 날짜로 계산할 경우
어떤 구매일로부터 다음 구매일까지의 간격을 알고 싶은 경우
- 데이터가 같은 테이블
- LAG 함수를 사용해 날짜 차이를 계
코드13-3
WITH
purchase_log(user_id, product_id, purchase_date) AS (
VALUES
('U001', '1', '2016-09-01')
, ('U001', '2', '2016-09-20')
, ('U002', '3', '2016-09-30')
, ('U001', '4', '2016-10-01')
, ('U002', '5', '2016-11-01')
)
SELECT
user_id
, purchase_date
, purchase_date::date
- LAG(purchase_date::date)
OVER(
PARTITION BY user_id
ORDER BY purchase_date
)
AS lead_time
FROM purchase_log
;
13-2. 카트 추가 후에 구매했는지 파악하기
💡 카트 탈락: 카트에는 넣었으나 구매 X(기준 필요, 교재에서는 48시간!)
- 상품 구매 절차의 문제
- 예상치 못한 비용(배송비 등)으로 인해 중단
- 북마크 기능 대신 카트 사용
⇒ 카트에서 실 구매로 이어지는 과정, 비율이 중요
코드 13-4. 상품들이 카트에 추가된 시각과 구매된 시각을 산출하는 쿼리

WITH
row_action_log as(
SELECT
dt
, user_id
, ACTION
--쉼표로 구분된 product_id 리스트 전개하기
, regexp_split_to_table(products, ',') AS product_id
, stamp
FROM action_log
)
, action_time_stats AS (
SELECT
user_id
, product_id
, MIN(CASE ACTION WHEN 'add_cart' THEN dt END ) AS dt
, MIN(CASE ACTION WHEN 'add_cart' THEN stamp END ) AS add_cart_time
, MIN(CASE ACTION WHEN 'purchase' THEN stamp END ) AS purchase_time
-- postgresql의 경우 timestamp 자료형으로 변환해서 간격을 구한 뒤 extract(epoc~)로 초 단위 변환
, EXTRACT(epoch FROM
min(CASE ACTION WHEN 'purchase' THEN stamp::timestamp END )
- min(CASE ACTION WHEN 'add_cart' THEN stamp::timestamp END ))
AS lead_time
FROM
row_action_log
GROUP BY
user_id, product_id
)
SELECT
user_id
, product_id
, add_cart_time
, purchase_time
, lead_time
FROM
action_time_stats
ORDER BY
user_id, product_id
;주요 문법
regexp_split_to_table(string 컬럼, '구분자')

EXTRACT 추가하기
코드13-5. 카트 추가 후 n시간 이내에 구매된 상품 수와 구매율을 집계하는 쿼리

WITH
row_action_log as(
SELECT
dt
, user_id
, ACTION
--쉼표로 구분된 product_id 리스트 전개하기
, regexp_split_to_table(products, ',') AS product_id
, stamp
FROM action_log
)
, action_time_stats AS (
SELECT
user_id
, product_id
, MIN(CASE ACTION WHEN 'add_cart' THEN dt END ) AS dt
, MIN(CASE ACTION WHEN 'add_cart' THEN stamp END ) AS add_cart_time
, MIN(CASE ACTION WHEN 'purchase' THEN stamp END ) AS purchase_time
-- postgresql의 경우 timestamp 자료형으로 변환해서 간격을 구한 뒤 extract(epoc~)로 초 단위 변환
, EXTRACT(epoch FROM
min(CASE ACTION WHEN 'purchase' THEN stamp::timestamp END )
- min(CASE ACTION WHEN 'add_cart' THEN stamp::timestamp END ))
AS lead_time
FROM
row_action_log
GROUP BY
user_id, product_id
)
-- 코드 13-4
, purchase_lead_time_flag AS (
SELECT
user_id
, product_id
, dt
, CASE WHEN lead_time <= 1 * 60 * 60 THEN 1 ELSE 0 END AS purchase_1_hour
, CASE WHEN lead_time <= 6 * 60 * 60 THEN 1 ELSE 0 END AS purchase_6_hours
, CASE WHEN lead_time <= 24 * 60 * 60 THEN 1 ELSE 0 END AS purchase_24_hours
, CASE WHEN lead_time <= 48 * 60 * 60 THEN 1 ELSE 0 END AS purchase_48_hours
, CASE
WHEN lead_time IS NULL OR NOT (lead_time <= 48 * 60 * 60 ) THEN 1
ELSE 0
END AS not_purchase
FROM
action_time_stats
)
SELECT
dt
, count(*) AS add_cart
, sum(purchase_1_hour) AS purchase_1_hour
, avg(purchase_1_hour) AS purchase_1_hour_rate
, sum(purchase_6_hours) AS purchase_6_hours
, avg(purchase_6_hours) AS purchase_6_hours_rate
, sum(purchase_24_hours) AS purchase_24_hours
, avg(purchase_24_hours) AS purchase_24_hours_rate
, sum(purchase_48_hours) AS purchase_48_hours
, avg(purchase_48_hours) AS purchase_48_hours_rate
, sum(not_purchase) AS not_purchase
, avg(not_purchase) AS not_purchase_rate
FROM
purchase_lead_time_flag
GROUP BY
dt
;13-3. 등록으로부터의 매출을 날짜 별로 집계하기
💡 목표: 이용기간에 따른 인당 매출액 산출
코드13-6. 사용자들의 등록일부터 경과한 일수 별 매출을 계산하는 쿼리
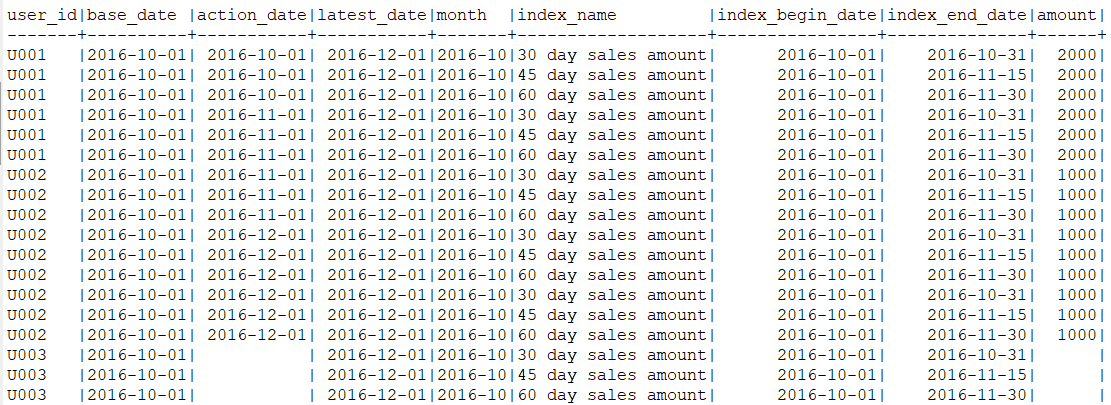
WITH
index_intervals(index_name, interval_begin_date, interval_end_date) AS (
VALUES
('30 day sales amount', 0, 30)
, ('45 day sales amount', 0, 45)
, ('60 day sales amount', 0, 60)
)
, mst_users_with_base_date AS (
SELECT
user_id
-- 기준일로 등록일 사용하기
, register_date AS base_date
FROM
mst_users
)
, purchase_log_with_index_date AS (
select
u.user_id
, u.base_date
-- 액션의 날짜와 로그 전체의 최신 날짜를 날짜 자료형으로 변환하기
, CAST(p.stamp AS date) AS action_date
, max(CAST(p.stamp AS date)) OVER() AS latest_date
, substring(u.base_date, 1 , 7) AS MONTH
, i.index_name
-- 지표 대상 기간의 시작일과 종료일 계산하기
, CAST(u.base_date::date + '1 day'::interval * i.interval_begin_date AS date)
AS index_begin_date
, CAST(u.base_date::date + '1 day'::interval * i.interval_end_date AS date)
AS index_end_date
, p.amount
FROM
mst_users_with_base_date AS u
LEFT OUTER JOIN
action_log AS p
ON u.user_id = p.user_id
AND p.ACTION = 'purchase'
CROSS JOIN
index_intervals AS i
)
SELECT *
FROM
purchase_log_with_index_date
;14강 사이트 전체의 특징/경향 찾기
14-1. 날짜 별 방문자 수 / 방문 횟수 / 페이지 뷰 집계하기
💡 웹사이트에서는 방문자 수, 방문 횟수, 페이지 뷰 집계가 기본!

코드14-1 날짜별 접근 데이터를 집계하는 쿼리
SELECT
-- substring으로 날짜 부분 추출하기
substring(stamp,1,10) as dt
-- substr(stamp,1,10) as dt
-- 쿠키 계산하기
,count(distinct long_session) as access_users
-- 방문 횟수 계산하기
,count(distinct short_session) as access_count
-- 페이지 뷰 계산하기
,count(*) as page_view
-- 1인당 페이지 뷰 수
-- NULLIF 함수 사용 가능
, 1.0 * COUNT(*) / NULLIF(COUNT(distinct long_session), 0) as pv_per_user
FROM
access_log
group by dt --select 구문에서 정의한 별칭을 group by에 지정할 수 있음
-- select 구문에서 별칭을 지정하기 이전의 식을 group by에 지정할 수 있음
-- substring(stamp, 1, 10)
order by dt
💡 문법
substring( 문자열, 시작점, 시작문자열갯수 )
NULLIF(ex1, ex2) : ex1값과 ex2값이 동일하면 NULL을 그렇지 않으면 ex1을 반환
- CASE WHEN ex1 = ex2 THEN NULL ELSE ex1 END 와 같음
- CASE WHEN <조건식> THEN <조건 만족 시 값> ELSE <조건 불만족 시 값> END
14-2. 페이지별 쿠키/ 방문 횟수/ 페이지 뷰 집계하기
💡 로그 데이터에는 URL이 포함된 경우가 多.
URL을 집계하면 각 페이지의 방문 횟수, 페이지 뷰 등을 집계할 수 있는데,
로그 데이터의 URL에는 요청 매개변수가 포함되는 경우도 多.
따라서 한 페이지를 가리키는 여러 URL이 존재하므로 단순한 방법으로는 페이지 뷰를 제대로 구할 수 없다.
코드14-2 URL별로 집계하는 쿼리
select url
,count(distinct short_session) as access_count
,count(distinct long_session) as access_users
,count(*) as page_view
from access_log
group by url
코드14-3 경로별로 집계하는 쿼리
with access_log_with_path as(
-- URL에서 경로 추출하기
select *
--정규 표현식으로 경로 부분 추출하기
, substring(url from '//[^/]+([^?#]+)') as url_path
from access_log
)
select url_path
, count(distinct short_session) as access_count
, count(distinct long_session) as access_users
, count(*) as page_view
from access_log_with_path
group by url_path
💡 문법
- substring ( 문자열, 시작점, 시작문자열갯수 )
- 로그 데이터에서 도메인 이하의 URL 경로와 GET방식으로 전송되는 특정 키와 값의 추출 이 필요할 때 :
substring(사이트 from '//[^/]+([^?#]+)') as 컬럼명
=‘/detail?id='을 ‘상세 페이지’라고 집계할 수 있게, 요청 매개변수를 생략하고, 경로만으로 집계
코드14-4. URL에 의미를 부여해서 집계하는 쿼리
💡 전체 페이지 뷰를 최상위 페이지, 카테고리/리스트 페이지, 상세페이지로 큰 밀도로 집계하는 방법
category_list와 newly_list에는 CASE 식으로 정의한 명칭, 이외의 경우는 경로를 기반으로 만들어진 이름이므로
‘/’이 포함되어 있음
with access_log_with_path as (
-- [코드 14-3] 참고하기
-- URL에서 경로 추출하기
select *
--정규 표현식으로 경로 부분 추출하기
, substring(url from '//[^/]+([^?#]+)') as url_path
from access_log
)
, access_log_with_split_path as(
select *
--split_part로 n번째 요소 추출하기
, split_part(url_path, '/', 2) as path1
, split_part(url_path, '/', 3) as path2
from access_log_with_path
)
, access_log_with_page_name as (
-- 경로를 슬래시로 분할하고, 조건에 따라 페이지 이름 붙이기
select *
, case
when path1 = 'list' then
case
when path2 = 'newly' then 'newly_list'
else 'category_list'
end
--이외의 경우는 경로를 그대로 사용하기
else url_path
end as page_name
from access_log_with_split_path
)
select page_name
,count(distinct short_session) as access_count
,count(distinct long_session) as access_users
,count(*) as page_view
from access_log_with_page_name
group by page_name
order by page_name💡 문법
- split_part(문자열, 자를문자(구분자), 위치)

14-3. 유입원별로 방문 횟수 또는 CVR 집계하기
💡 유입 경로를 개별적으로 집계하면, 웹사이트의 방문자가 어떤 행동을 해서 우리 웹사이트에
방문 하는 것인지 알 수 있음.
- 주요 유입 경로
- 검색 엔진
- 검색 연동형 광고
- 트위터, 페이스북 등의 소셜 미디어
- 제휴 사이트
- 광고 네트워크(ad network)
- 다른 웹사이트에 붙은 링크(블로그 소개 기사 등)
- 유입원 판정
- URL 매개변수 기반 판정(레퍼러(referer) : 직전 페이지의 URL)
- 래퍼러 도메인과 랜딩 페이지를 사용한 판정
- CVR이란?
- 전환율(Conversion Rate)을 의미. 이 CVR 수치가 상승하게 되면 큰 성과를 얻었다는 의미로 해석. 이 수치는 굳이 실제 구매가 이루어지지 않아도 특정 액션, 즉 어플을 설치하거나 설문지 참여, 회원가입, 상담문의 등이 일어 났을 때 전환률은 오르게 됨.
- 전환율은 전환수를 방문자수로 나누어 계산. 보통 퍼센티지 단위 사용.
- URL 매개변수를 사용하면 다양한 유입 계측이 가능

- 유입원별 방문 횟수 집계하기
- 이번 절에서 소개할 SQL은 레퍼러가 있는 경우, 해당 도메인이 자신의 사이트가 아닌 경우라는 두 가지 조건을 만족할 때 다음과 같은 로직으로 유입원별 방문 횟수를 집계

코드 14-5. (유입원별로 방문 횟수를 집계하는 쿼리)
WITH
access_log_with_parse_info AS (
-- 유입원 정보 추출하기
SELECT *
-- PostgreSQL, 정규 표현식으로 유입원 정보 추출하기
, substring(url from 'https?://([^/]*)') AS url_domain
, substring(url from 'utm_source=([^&]*)') AS url_utm_source
, substring(url from 'utm_medium=([^&]*)') AS url_utm_medium
, substring(referrer from 'https?://([^/]*)') AS referer_domain
FROM access_log
)
, access_log_with_via_info AS (
SELECT *
, ROW_NUMBER() OVER(ORDER BY stamp) AS log_id
, CASE
WHEN url_utm_source <> '' AND url_utm_medium <> ''
-- PostgreSQL, Hive, BigQuery, SpaerkSQL, concat 함수에 여러 매개변수 사용 가능
--THEN concat(url_utm_source, '-', url_utm_medium) 이 코드로 수행해도 됨.
-- PostgreSQL, Redshift, 문자열 결합에 ||(or) 연산자 사용
THEN url_utm_source || '-' || url_utm_medium
WHEN referer_domain IN ('search.yahoo.co.jp', 'www.google.co.jp') THEN 'search'
WHEN referer_domain IN ('twitter.com', 'www.facebook.com') THEN 'social'
ELSE 'other'
-- ELSE referer_domain으로 변경하면, 도메인별 집계 가능
END AS via
FROM access_log_with_parse_info
-- 리퍼러가 없는 경우와 우리 사이트 도메인의 경우 제외
WHERE COALESCE(referer_domain, '') NOT IN ('', url_domain)
)
SELECT via, COUNT(1) AS access_count
FROM access_log_with_via_info
GROUP BY via
ORDER BY access_count DESC;
- 유입원별로 CVR 집계하기
- WITH 구문의 access_log_with_purchase_amount 테이블을 수정하면 다양하게 사용 가능.
코드 14-6. (각 방문에서 구매한 비율(CVR)을 집계하는 쿼리)
WITH
access_log_with_parse_info AS (
-- 유입원 정보 추출하기
SELECT *
-- PostgreSQL, 정규 표현식으로 유입원 정보 추출하기
, substring(url from 'https?://([^/]*)') AS url_domain
, substring(url from 'utm_source=([^&]*)') AS url_utm_source
, substring(url from 'utm_medium=([^&]*)') AS url_utm_medium
, substring(referrer from 'https?://([^/]*)') AS referer_domain
FROM access_log
)
, access_log_with_via_info AS (
SELECT *
, ROW_NUMBER() OVER(ORDER BY stamp) AS log_id
, CASE
WHEN url_utm_source <> '' AND url_utm_medium <> ''
-- PostgreSQL, Hive, BigQuery, SpaerkSQL, concat 함수에 여러 매개변수 사용 가능
--THEN concat(url_utm_source, '-', url_utm_medium) 이 코드로 수행해도 됨.
-- PostgreSQL, Redshift, 문자열 결합에 ||(or) 연산자 사용
THEN url_utm_source || '-' || url_utm_medium
WHEN referer_domain IN ('search.yahoo.co.jp', 'www.google.co.jp') THEN 'search'
WHEN referer_domain IN ('twitter.com', 'www.facebook.com') THEN 'social'
ELSE 'other'
-- ELSE referer_domain으로 변경하면, 도메인별 집계 가능
END AS via
FROM access_log_with_parse_info
-- 리퍼러가 없는 경우와 우리 사이트 도메인의 경우 제외
WHERE COALESCE(referer_domain, '') NOT IN ('', url_domain)
)
, access_log_with_purchase_amount AS (
SELECT
a.log_id
, a.via
, SUM(
CASE
-- PostgreSQL, interval 자료형의 데이터로 날짜와 시간 사칙연산 가능
WHEN p.stamp::date BETWEEN a.stamp::date AND a.stamp::date + '1 day'::interval
THEN amount
END
) AS amount
FROM
access_log_with_via_info AS a
LEFT OUTER JOIN
purchase_log AS p
ON a.long_session = p.long_session
GROUP BY a.log_id, a.via
)
SELECT
via
, COUNT(1) AS via_count
, COUNT(amount) AS conversions
, AVG(100.0 * SIGN(COALESCE(amount, 0))) AS cvr
, SUM(COALESCE(amount, 0)) AS amount
, AVG(1.0 * COALESCE(amount, 0)) AS avg_amount
FROM
access_log_with_purchase_amount
GROUP BY via
ORDER BY cvr desc
;
14-4. 접근 요일, 시간대 파악하기
- 사용자가 접근하는 요일과 시간대는 서비스에 따라 특징이 있음.
- 이런 특성을 파악하면 공지사항 또는 메일 매거진 발신 시점, 캠페인 시작 지점과 종료 시점 등을 검토할 때 활용 가능.
- 외부 미디어에 대한 노출이 순간 증가했을 때, 공지사항 또는 메일 매거진을 전달하면 효과가 큼.
❗요일 번호를 추출하는 SQL 구문은 미들웨어에 따라 다름 주의

코드 14-7. (요일/시간대별 방문자 수를 집계하는 쿼리)
WITH
access_log_with_dow AS (
SELECT
stamp
-- 일요일(0)부터 토요일(6)까지의 요일 번호 추출하기
-- PostgreSQL, Redshift의 경우 date_part 함수 사용하기
-- ::는 데이터 형식 변환
, date_part('dow', stamp::timestamp) AS dow
-- 00:00:00부터의 경과 시간을 초 단위로 계산
-- PostgreSQL, Hive, Redshift, SparkSQL
-- substring 함수를 사용해 시, 분, 초를 추출하고 초 단위로 환산하여 더하기
-- BigQuery의 경우 substring을 substr, int를 int64로 수정하기
, CAST(substring(stamp, 12, 2) AS int) * 60 * 60
+ CAST(substring(stamp, 15, 2) AS int) * 60
+ CAST(substring(stamp, 18, 2) AS int)
AS whole_seconds
-- 시간 간격 정하기
-- 현재 예제에서는 30분(1800초)으로 지정하기
, 30 * 60 AS interval_seconds
FROM access_log
)
, access_log_with_floor_seconds AS (
SELECT
stamp
, dow
-- 00:00:00부터의 경과 시간을 interval_seconds로 나누기
-- PostgreSQL, Hive, Redshift, SparkSQL의 경우는 다음과 같이 사용하기
-- BigQuery의 경우 int를 int64로 수정하기
, CAST((floor(whole_seconds / interval_seconds) * interval_seconds) AS int)
AS floor_seconds
FROM access_log_with_dow
)
, access_log_with_index AS (
SELECT
stamp
, dow
-- 초를 다시 타임스탬프 형식으로 변환하기
-- PostgreSQL, Redshift의 경우는 다음과 같이 하기
, lpad(floor(floor_seconds / (60 * 60))::text, 2, '0') || ':'
|| lpad(floor(floor_seconds % (60 * 60) / 60)::text, 2, '0') || ':'
|| lpad(floor(floor_seconds % 60)::text, 2, '0')
AS index_time
FROM access_log_with_floor_seconds
)
SELECT
index_time
, COUNT(CASE dow WHEN 0 THEN 1 END) AS sun
, COUNT(CASE dow WHEN 1 THEN 1 END) AS mon
, COUNT(CASE dow WHEN 2 THEN 1 END) AS tue
, COUNT(CASE dow WHEN 3 THEN 1 END) AS wed
, COUNT(CASE dow WHEN 4 THEN 1 END) AS thu
, COUNT(CASE dow WHEN 5 THEN 1 END) AS fri
, COUNT(CASE dow WHEN 6 THEN 1 END) AS sat
FROM
access_log_with_index
GROUP BY
index_time
ORDER BY
index_time
;SUBSTRING(str, pos, len)str에서pos번째 위치에서len개의 문자를 읽어 들인다.
- LPAD("값", "총 문자길이", "채움문자") : LPAD(123, 8, '0') → 결과: 00000123

728x90
'IT > SQL' 카테고리의 다른 글
| [데이터 분석을 위한 SQL 레시피] 6장 16강 입력 양식 최적화하기 (2) | 2023.06.19 |
|---|---|
| [데이터 분석을 위한 SQL 레시피] 6장 15강 사이트 내의 사용자 행동 파악하기 (0) | 2023.06.19 |
| [데이터 분석을 위한 SQL 레시피] 5장 12강 시계열에 따른 사용자 전체의 상태 변화 찾기_part2(p.275~p.302) (0) | 2023.06.17 |
| [데이터 분석을 위한 SQL 레시피] 5장 12강 시계열에 따른 사용자 전체의 상태 변화 찾기_part1(p.233~p.275) (0) | 2023.06.17 |
| [데이터 분석을 위한 SQL 레시피] 5장 11강. 사용자 전체의 특징과 경향 찾기 (0) | 2023.06.17 |
Contents
소중한 공감 감사합니다