IT/SQL
[데이터 분석을 위한 SQL 레시피] 5장 11강. 사용자 전체의 특징과 경향 찾기
- -
728x90
반응형
💡 사용자의 속성 또는 행동과 관련된 정보를 집계해서 사용자 행동을 조사하고, 서비스를 개선할 때 실마리가 될 수 있는 리포트를 만드는 SQL을 학습.
사용 데이터
- mst_users: 사용자 마스터 테이블 —> 기준 column은 user_id(사용자)

- action_log: 사용자 로그 테이블 —> 기준 column은 session(각 접속 시기)

11-1. 사용자의 액션 수 집계하기
액션과 관련된 지표 집계하기
- 사용자들이 특정 기간 동안 기능을 얼마나 사용하는지 집계.
- 사용률(usage_rate)과 1명당 액션 수(count_per_user)를 계산
code 11-1.(액션 수와 비율을 계산하는 쿼리)
WITH
stats AS (
-- 로그 전체의 유니크 사용자 수 구하기
SELECT COUNT(DISTINCT session) AS total_uu
FROM action_log
)
SELECT
l.action
-- 액션 UU
, COUNT(DISTINCT l.session) AS action_uu
-- 액션 수
, COUNT(1) AS action_count
-- 전체 UU
, s.total_uu
-- 사용률 = <액션 UU> / <전체 UU>
, 100.0 * COUNT(DISTINCT l.session) / s.total_uu AS usage_rate
-- 1인당 액션 수 = <액션 수> / <액션 UU>
, COUNT(l) / COUNT(DISTINCT l.session) AS count_per_user
FROM
action_log AS l
-- 로그 전체의 유니크 사용자 수를 모든 레코드(action_log)에 결합하기
CROSS JOIN
stats AS s
GROUP BY
l.action, s.total_uu
;- UU는 Unique Users를 나타내는 중복 없이 집계된 사용자 수를 나타내는 말. 페이지 열람 UU라고 하면, 페이지를 열었던 사용자 수를 중복 없이 집계한 것이라고 생각하면 됨.
- COUNT() : NULL 속성 값은 제외하고 계산됨. 개수 집계함수.
- DISTINCT : 중복 허용 x.

로그인 사용자와 비로그인 사용자를 구분해서 집계하기
- 서비스에 대한 충성도가 높은 사용자와 낮은 사용자가 어떤 경향을 보이는지 발견 할 수 있다.
code 11-2.(로그인 상태를 판별하는 쿼리)
WITH action_log_with_status AS (
SELECT session, user_id, action
-- user_id가 NULL 또는 빈 문자('')가 아닌 경우 login 상태로 판단
, CASE WHEN COALESCE(user_id, '') <> '' THEN 'login' ELSE 'guest' END
AS login_status
FROM action_log
)
SELECT *
FROM action_log_with_status;- WITH : 가상 테이블을 만드는 구분. 만들어진 가상 테이블은 여러 번 참조 가능.
- COALESCE() : 인자로 주어진 칼럼들 중에서 NULL이 아닌 첫 번째 값을 반환하는 함수.
- COALESCE(user_id, ' ') : user_id 열의 NULL 값을 ' '으로 변환

code 11-3.(로그인 상태에 따라 액션 수 등을 따로 집계하는 쿼리)
WITH
action_log_with_status AS (
--코드 11-2 참고하기
SELECT session, user_id, action
-- user_id가 NULL 또는 빈 문자('')가 아닌 경우 login 상태로 판단, 아니면 guest
, CASE WHEN COALESCE(user_id, '') <> '' THEN 'login' ELSE 'guest' END
AS login_status
FROM action_log
)
SELECT
COALESCE(action, 'all') AS action
, COALESCE(login_status, 'all') AS login_status
, COUNT(DISTINCT session) AS action_uu
, COUNT(1) AS action_count
FROM
action_log_with_status
GROUP BY ROLLUP(action, login_status);
회원과 비회원을 구분해서 집계하기
- 로그인, 비로그인 상태의 사용자만 구분하고 싶다면 코드 11-3으로도 문제가 없지만, 로그인 하지 않은 상태라도, 이전에 한 번이라도 로그인했다면 회원으로 계산하고 싶을 수 있음.
code 11-4.(회원 상태를 판별하는 쿼리)
WITH action_log_with_status AS (
SELECT
session, user_id, action
-- log를 타임스탬프 순으로 나열, 한번이라도 로그인했을 경우,
-- 이후의 모든 로그 상태를 member로 설정
, CASE
WHEN
COALESCE(MAX(user_id)
OVER(PARTITION BY session ORDER BY stamp
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
, '') <> ''
THEN 'member'
ELSE 'none'
END AS member_status
, stamp
FROM action_log
)
SELECT *
FROM action_log_with_status;- OVER( ): 다수의 집계함수를 나열하기 위한 구문.

11-2. 연령별 구분 집계하기
- 표 11-2 연령별 구분 목록

code 11-5.(성별과 연령으로 연령별 구분을 계산하는 쿼리)
WITH
mst_users_with_int_birth_date AS(
SELECT
*
--특정날짜 (2017년 1월 1일)의 정수 표현
, 20170101 AS int_specific_date
--문자열로 구성된 생년월일을 정수 표현으로 변환하기
, CAST(replace(substring(birth_date, 1, 10), '-', '') AS integer) AS int_birth_date
FROM
mst_users
)
, mst_users_with_age AS (
SELECT
*
-- 특정날짜 (2017년 1월 1일)의 나이
, floor((int_specific_date - int_birth_date) / 1000) AS age
FROM
mst_users_with_int_birth_date
)
SELECT
user_id, sex, birth_date, age
FROM
mst_users_with_age
;- CAST('[변환하고자 하는 데이터]' AS [데이터형식])
- REPLACE(A, B, C) : A의 문자열 중 B를 C로 바꿔줌.
- 생일과 날짜를 정수로 표현하고(6장 5절 참고), 그 차이를 10,000으로 나누는 방법으로 나이 구현.

code 11-6.(성별과 연령으로 연령별 구분을 계산하는 쿼리)
WITH
mst_users_with_int_birth_date AS (
-- 코드 11-5 참고하기
SELECT *
-- 특정 날짜(2017-01-01)의 정수 표현
, 20170101 AS int_specific_date
-- 문자열로 구성된 생년월일을 정수 표현으로 변환
, CAST(replace(substring(birth_date, 1, 10), '-', '') AS integer) AS int_birth_date
FROM
mnt_users
)
, mst_users_with_age AS (
-- 코드 11-5 참고하기
SELECT *
-- 특정 날짜(2017-01-01)의 나이
, floor((int_specific_date - int_birth_date) / 10000) AS age
FROM mst_users_with_int_birth_date
)
, mst_users_with_category AS (
SELECT user_id, sex, age
, CONCAT (
CASE
WHEN 20 <= age THEN sex
ELSE ''
END
, CASE
WHEN age BETWEEN 4 AND 12 THEN 'C'
WHEN age BETWEEN 13 AND 19 THEN 'T'
WHEN age BETWEEN 20 AND 34 THEN '1'
WHEN age BETWEEN 35 AND 49 THEN '2'
WHEN age >= 50 THEN '3'
END
) AS category
FROM mst_users_with_age
)
SELECT *
FROM mst_users_with_category;- 결과

code 11-7
WITH
mst_users_with_int_birth_date AS (
-- 코드 11-5 참고하기
SELECT *
-- 특정 날짜(2017-01-01)의 정수 표현
, 20170101 AS int_specific_date
-- 문자열로 구성된 생년월일을 정수 표현으로 변환
, CAST(replace(substring(birth_date, 1, 10), '-', '') AS integer) AS int_birth_date
FROM
mst_users
)
, mst_users_with_age AS (
-- 코드 11-5 참고하기
SELECT *
-- 특정 날짜(2017-01-01)의 나이
, floor((int_specific_date - int_birth_date) / 10000) AS age
FROM mst_users_with_int_birth_date
)
, mst_users_with_category AS (
SELECT user_id, sex, age
, CONCAT (
CASE
WHEN 20 <= age THEN sex
ELSE ''
END
, CASE
WHEN age BETWEEN 4 AND 12 THEN 'C'
WHEN age BETWEEN 13 AND 19 THEN 'T'
WHEN age BETWEEN 20 AND 34 THEN '1'
WHEN age BETWEEN 35 AND 49 THEN '2'
WHEN age >= 50 THEN '3'
END
) AS category
FROM mst_users_with_age
)
SELECT
category
, COUNT(1) AS user_count
FROM
mst_users_with_category
GROUP BY
category
;
11-3. 연령별 구분의 특징 집계하기
💡 SQL : JOIN, GROUP BY 분석 : 연령별 구분
🔖 ABC 분석과 구성비누계를 리포트를 추가하면, 리포트의 내용 전달성을 향상시킬 수 있다.
사용자의 속성에 맞춰 상품 또는 기사를 추천할 수 있다.
code 11-8
연령별 구분과 카테고리를 집계하는 쿼리
WITH
mst_users_with_int_birth_date AS (
-- 코드 11-5 참고하기
SELECT *
-- 특정 날짜(2017-01-01)의 정수 표현
, 20170101 AS int_specific_date
-- 문자열로 구성된 생년월일을 정수 표현으로 변환
, CAST(replace(substring(birth_date, 1, 10), '-', '') AS integer) AS int_birth_date
FROM
mst_users
)
, mst_users_with_age AS (
-- 코드 11-5 참고하기
SELECT *
-- 특정 날짜(2017-01-01)의 나이
, floor((int_specific_date - int_birth_date) / 10000) AS age
FROM mst_users_with_int_birth_date
)
, mst_users_with_category AS (
SELECT user_id, sex, age
, CONCAT (
CASE
WHEN 20 <= age THEN sex
ELSE ''
END
, CASE
WHEN age BETWEEN 4 AND 12 THEN 'C'
WHEN age BETWEEN 13 AND 19 THEN 'T'
WHEN age BETWEEN 20 AND 34 THEN '1'
WHEN age BETWEEN 35 AND 49 THEN '2'
WHEN age >= 50 THEN '3'
END
) AS category
FROM mst_users_with_age
)
SELECT
p.category AS product_category
, u.category AS user_category
, COUNT(*) AS purchase_count
FROM
action_log AS p
JOIN
mst_users_with_category AS u ON p.user_id = u.user_id
WHERE
-- 구매 로그만 선택
action = 'purchase'
GROUP BY
p.category, u.category
ORDER BY
p.category, u.category
;
11-4. 사용자의 방문 빈도 집계하기
💡 SQL : SUM 윈도우 함수 분석 : 방문 빈도
🔖 서비스를 한 주 동안 며칠 사용하는 사용자가 몇 명인지 집계하는 방법
매일 방문하는 사용자 와 일주일에 한 번만 방문하는 사용자 행동 패턴에는 큰 차이가 존재
code 11-9
한 주에 며칠 사용되었는지를 집계하는 쿼리
action_log테이블- 사용자 ID, 액션, 날짜
- 사용자 ID별로
DISTINCT를 적용하여 사용 일 수 집계 - 로그에 시각까지 기록되어 있는 경우, 시각 부분을 떼어버리면 됨
WITH
action_log_with_dt AS (
SELECT *
-- 타임 스탬프에서 날짜 추출하기
-- PostgreSQL, Hive, Redshift, SparkSQL의 경우 substring으로 날짜 추출
, substring(stamp, 1, 10) AS dt
-- PostgerSQL, Hive, BigQuery, SparkSQL의 경우 substr 사용
-- , substring(stamp, 1, 10) AS dt
FROM action_log
)
, action_day_count_per_user AS (
SELECT
user_id
, COUNT(DISTINCT dt) AS action_day_count
FROM
action_log_with_dt
WHERE
-- 2016년 11월 1일부터 11월 7일까지의 한 주 동안을 대상으로 지정
dt BETWEEN '2016-11-01' AND '2016-11-07'
GROUP BY
user_id
)
SELECT
action_day_count
, COUNT(DISTINCT user_id) AS user_count
FROM
action_day_count_per_user
GROUP BY
action_day_count
ORDER BY
action_day_count
;
code 11-10
구성비와 구성비 누계를 계산하는 쿼리
WITH
action_day_count_per_user AS (
-- [코드 11-9] 참고
)
SELECT
action_day_count
, COUNT(DISTINCT user_id) AS user_count
-- 구성비
, 100.0
* COUNT(DISTINCT user_id)
/ SUM(COUNT(DISTINCT user_id)) OVER()
AS composition_ratio
-- 구성비누계
, 100.0
* SUM(COUNT(DISTINCT user_id))
OVER(ORDER BY action_day_count
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
/ SUM(COUNT(DISTINCT user_id)) OVER()
AS cumulative_ratio
FROM
action_day_count_per_user
GROUP BY
action_day_count
ORDER BY
action_day_count
;
11-5. 벤 다이어그램으로 사용자 액션 집계하기
💡 SQL : SIGN 함수, SUM 함수, CASE 식, CUBE 구문 분석 : 벤 다이어그램
🔖 벤 다이어그램으로 확인하면, 대책을 제대로 세웠는지(대상을 제대로 가정했는지 등) 확인할 수 있다.
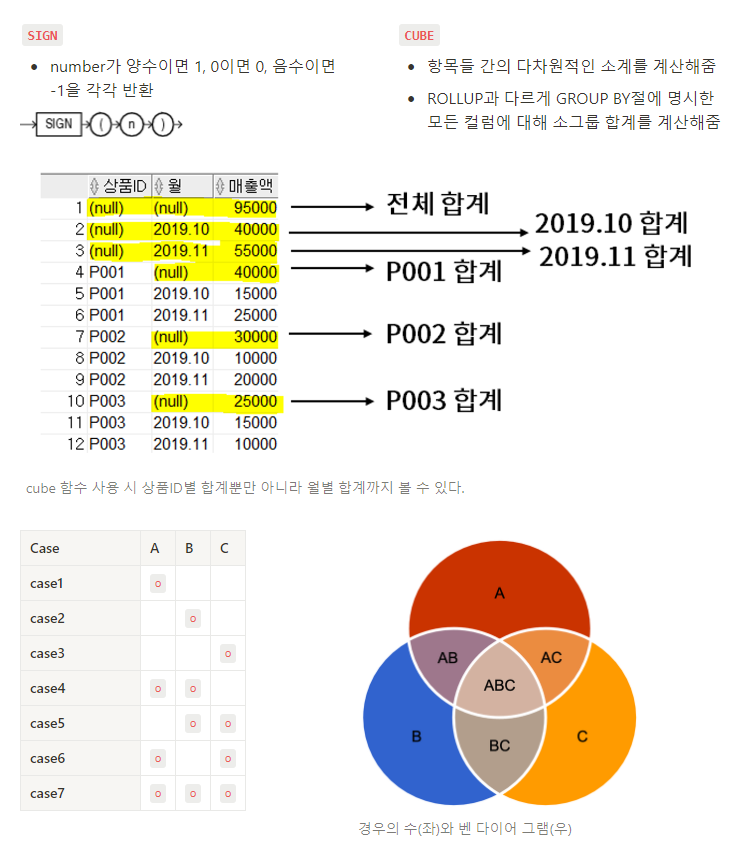
사건이 서로 독립적이며 동시 발생 가능한 경우, 경우의 수를 벤 다이어그램으로 정리할 수 있다.
이를 통해 사용자들의 행동 패턴을 분석해보자!
code 11-11
사용자들의 액션 플래그를 집계하는 쿼리
WITH
user_action_flag AS (
-- 사용자가 액션을 했으면 1, 안 했으면 0으로 플래그 붙이기
SELECT user_id
, sign(sum(CASE WHEN ACTION='purchase' THEN 1 ELSE 0 end)) AS has_purchase
, sign(sum(CASE WHEN ACTION='review' THEN 1 ELSE 0 end)) AS has_review
, sign(sum(CASE WHEN ACTION='favorite' THEN 1 ELSE 0 end)) AS has_favorite
FROM action_log
GROUP BY user_id
)
SELECT *
FROM user_action_flag;
code 11-12
모든 액션 조합에 대한 사용자 수 계산하기
WITH
user_action_flag AS (
-- [코드 11-11] 참고하기
-- 사용자가 액션을 했으면 1, 안 했으면 0으로 플래그 붙이기
SELECT user_id
, sign(sum(CASE WHEN ACTION='purchase' THEN 1 ELSE 0 end)) AS has_purchase
, sign(sum(CASE WHEN ACTION='review' THEN 1 ELSE 0 end)) AS has_review
, sign(sum(CASE WHEN ACTION='favorite' THEN 1 ELSE 0 end)) AS has_favorite
FROM action_log
GROUP BY user_id
)
, action_venn_diagram AS (
--CUBE를 사용해서 모든 액션 조합 구히기)
SELECT has_purchase
, has_review
, has_favorite
, count(1) AS users
FROM user_action_flag
GROUP BY
CUBE(has_purchase, has_review, has_favorite)
)
SELECT *
FROM user_action_flag;
code 11-13. CUBE 구문 없이 표준 SQL구문만으로 작성한 쿼리
- union all을 반복 사용하므로, 성능이 좋지 않다.

WITH
user_action_flag as(
-- 사용자가 action을 했으면 1, 아니면 0으로 플래그
SELECT
user_id
, sign(sum(CASE WHEN ACTION = 'purchase' THEN 1 ELSE 0 end)) AS has_purchase
, sign(sum(CASE WHEN ACTION = 'review' THEN 1 ELSE 0 end)) AS has_review
, sign(sum(CASE WHEN ACTION = 'favorite' THEN 1 ELSE 0 end)) AS has_favorite
FROM
action_log
GROUP BY
user_id
)
, action_venn_diagram as(
--모든 액션 조합을 개별적으로 구하고 union all 로 결합
--case1. 3개의 action 모두 한 경우 집계
SELECT has_purchase, has_review, has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_purchase, has_review, has_favorite
--case 2. 리뷰, 좋아요만 한 경우
UNION all
SELECT NULL AS has_purchase, has_review, has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_review, has_favorite
--case 3. 구매, 좋아요만 한 경우
UNION all
SELECT has_purchase, NULL AS has_review, has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_purchase, has_favorite
--case 4. 구매, 리뷰만 한 경우
UNION all
SELECT has_purchase, has_review, NULL AS has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_purchase, has_review
--case 5. 좋아요만
UNION all
SELECT NULL AS has_purchase, NULL AS has_review, has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_favorite
--case 6. 리뷰만
UNION all
SELECT NULL AS has_purchase, has_review, NULL AS has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_review
--case 7. 구매만
UNION all
SELECT has_purchase, NULL AS has_review, NULL AS has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_purchase
-- 액션과 상관 없이 모든 사용자 집계
UNION ALL
SELECT NULL AS has_purchase, NULL AS has_review, NULL AS has_favorite, count(1) AS users
FROM user_action_flag
)
SELECT *
FROM action_venn_diagram
ORDER BY
has_purchase, has_review, has_favorite;code 11-14 NULL 포함한 레코드를 추가, CUBE구문과 같은 결과를 얻는 쿼리
- postgreSQL의 cube문을 대체하기 위한 다른 SQL언어 기준의 쿼리입니다. 저희 언어에서는 작동하지 않기에 생략하겠습니다.
code 11-15. 벤 다이어그램을 만들기 위해 데이터를 관리하는 쿼리

-- with 절은 위의 11-13 코드와 동일!!
WITH
user_action_flag as(
-- 사용자가 action을 했으면 1, 아니면 0으로 플래그
SELECT
user_id
, sign(sum(CASE WHEN ACTION = 'purchase' THEN 1 ELSE 0 end)) AS has_purchase
, sign(sum(CASE WHEN ACTION = 'review' THEN 1 ELSE 0 end)) AS has_review
, sign(sum(CASE WHEN ACTION = 'favorite' THEN 1 ELSE 0 end)) AS has_favorite
FROM
action_log
GROUP BY
user_id
)
, action_venn_diagram as(
--모든 액션 조합을 개별적으로 구하고 union all 로 결합
--case1. 3개의 action 모두 한 경우 집계
SELECT has_purchase, has_review, has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_purchase, has_review, has_favorite
--case 2. 리뷰, 좋아요만 한 경우
UNION all
SELECT NULL AS has_purchase, has_review, has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_review, has_favorite
--case 3. 구매, 좋아요만 한 경우
UNION all
SELECT has_purchase, NULL AS has_review, has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_purchase, has_favorite
--case 4. 구매, 리뷰만 한 경우
UNION all
SELECT has_purchase, has_review, NULL AS has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_purchase, has_review
--case 5. 좋아요만
UNION all
SELECT NULL AS has_purchase, NULL AS has_review, has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_favorite
--case 6. 리뷰만
UNION all
SELECT NULL AS has_purchase, has_review, NULL AS has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_review
--case 7. 구매만
UNION all
SELECT has_purchase, NULL AS has_review, NULL AS has_favorite, count(1) AS users
FROM user_action_flag
GROUP BY has_purchase
-- 액션과 상관 없이 모든 사용자 집계
UNION ALL
SELECT NULL AS has_purchase, NULL AS has_review, NULL AS has_favorite, count(1) AS users
FROM user_action_flag
)
-- with 절은 위의 11-13 코드와 동일!!
SELECT
-- 0,1 플래그를 문자열로 가공하기
CASE has_purchase
WHEN 1 THEN 'purchase' WHEN 0 THEN 'not purchase' ELSE 'any'
END AS has_purchase
, CASE has_review
WHEN 1 THEN 'review' WHEN 0 THEN 'not review' ELSE 'any'
END AS has_review
, CASE has_favorite
WHEN 1 THEN 'favorite' WHEN 0 THEN 'not favorite' ELSE 'any'
END AS has_favorite
,users
-- 전체 사용자 수 기반으로 비율 구하기
, 100.0*users
/NULLIF(
-- 모든 액션이 null인 사용자 수가 전체 사용자 수이므로,
-- 해당 레코드의 사용자 수를 window 함수로 구하기
sum(CASE WHEN has_purchase IS NULL
AND has_review IS NULL
AND has_favorite IS NULL
THEN users ELSE 0 END) over()
, 0)
AS ration
FROM
action_venn_diagram
ORDER BY
has_purchase, has_review, has_favorite
;11-6. Decile 분석을 사용해 사용자를 10단계 그룹으로 나누기
Decile 분석이란?
- decile : 10분의 1
- ⇒ 사용자를 매출 등의 기준으로 10등분, 등급 별 매출액과 전체 누적 매출액을 한 그래프에 집계
- 꼭 등급 별 매출액과 누계가 아니더라도, 표본을 10등분하여 분석하는 데이터 분석 기법을
- decile analysis라고 칭함

code 11-16. 구매액이 많은 순서로 사용자 그룹을 10등분하는 쿼리

WITH
user_purchase_amount AS(
SELECT
user_id
, sum(amount) AS purchase_amount
FROM
action_log WHERE
ACTION = 'purchase'
GROUP BY
user_id
)
, users_with_decile AS (
SELECT
user_id
,purchase_amount
, ntile(10) over(ORDER BY purchase_amount desc) AS decile
FROM
user_purchase_amount
)
SELECT *
FROM users_with_decile
;이제 사용자 별 decile 구간이 주어졌으므로, decile을 group by 하여 (= decile 기준으로) 정보를 집계할 수 있게 되었습니다. 11-16 쿼리를 활용하여 추가 집계를 진행해봅시다.
code 11-17. 10분할한 decile을 집계하는 쿼리
decile 기준으로 정보를 집계한다면, 다음과 같은 결과가 나올 것입니다. 이를 도출하는 쿼리를 작성해봅시다.

WITH
user_purchase_amount AS(
SELECT
user_id
, sum(amount) AS purchase_amount
FROM
action_log WHERE
ACTION = 'purchase'
GROUP BY
user_id
)
, users_with_decile AS (
SELECT
user_id
,purchase_amount
, ntile(10) over(ORDER BY purchase_amount desc) AS decile
FROM
user_purchase_amount
)
--16번 쿼리에서 새로 추가된 내용 시작
, decile_with_purchase_amount AS (
SELECT
decile
, sum(purchase_amount) AS amount
, avg(purchase_amount) AS avg_amount
, sum(sum(purchase_amount)) OVER (ORDER BY decile) AS cumulative_amount
, sum(sum(purchase_amount)) OVER () AS total_amount
FROM
users_with_decile
GROUP BY
decile
)
SELECT *
FROM decile_with_purchase_amount
;이제 decile을 기준으로 매출의 평균과 누계, 총합을 나눌 수 있습니다. 나아가 구성비와 구성비 누계를 집계해보겠습니다.
code 11-18. 구매액이 많은 순서대로 구성비와 구성비 누계를 계산하는 쿼리

WITH
user_purchase_amount AS(
SELECT
user_id
, sum(amount) AS purchase_amount
FROM
action_log WHERE
ACTION = 'purchase'
GROUP BY
user_id
)
, users_with_decile AS (
SELECT
user_id
,purchase_amount
, ntile(10) over(ORDER BY purchase_amount desc) AS decile
FROM
user_purchase_amount
)
--16번 쿼리에서 새로 추가된 내용 시작
, decile_with_purchase_amount AS (
SELECT
decile
, sum(purchase_amount) AS amount
, avg(purchase_amount) AS avg_amount
, sum(sum(purchase_amount)) OVER (ORDER BY decile) AS cumulative_amount
, sum(sum(purchase_amount)) OVER () AS total_amount
FROM
users_with_decile
GROUP BY
decile
)
-- 18번 쿼리에서 추가된 부분
SELECT
decile
, amount
, avg_amount
, 100.0 * amount / total_amount AS total_ratio
, 100.0 * cumulative_amount / total_amount AS cumulative_ratio
FROM
decile_with_purchase_amount;Decile 분석 활용안
Decile analysis의 기준이 어떤 수치냐에 따라, 각 집단의 특성을 정의하고 분석할 수 있습니다.
가령 매출 기준 7분위~10분위 집단은 정착되지 않은 고객일 수 있습니다. 교재에서는
- email 등을 통해 해당 고객들에게 유인을 제공하고,
- 컨텐츠 / 접촉에 대한 고객들의 반응을 수집하여 추가 데이터 분석을 제안하고 있습니다.
11-7. RFM분석으로 사용자를 3가지 관점의 그룹으로 나누기
RFM분석 : 사용자의 구매 금액 합계를 기반으로 사용자를 10개의 그룹으로 분할하는 Decile 분석보다도 자세하게 사용자를 그룹으로 나눌 수 있는 분석 방법.
- Recency : 최근 구매일
- 최근 무언가를 구매한 사용자를 우량 고객으로 취급
- Frequency : 구매 횟수
- 사용자가 구매한 횟수를 세고, 많을수록 우량 고객으로 취급
- Monetary : 구매 금액 합계
- 사용자의 구매 금액 합계를 집계하고, 금액이 높을수록 우량 고객으로 취급code 11-19
code 11-19. 사용자별로 RFM을 집계하는 쿼리
WITH
purchase_log AS (
SELECT
user_id
, amount
-- 타임스탬프를 기반으로 날짜 추출하기
-- ■ PostgreSQL, Hive, Redshift, SparkSQL의 경우 substring으로 날짜 부분 추출하기
, substring(stamp, 1, 10) AS dt
-- ■ PostgreSQL, Hive, Redshift, SparkSQL의 경우 substr 사용하기
-- , substr(stamp, 1, 10) AS dt
FROM
action_log
WHERE
ACTION = 'purchase'
)
, user_rfm AS(
SELECT
user_id
, max(dt) AS recent_date
-- ■ PostgreSQL, Redshift의 경우 날짜 형식끼리 빼기 연산 가능
, current_date - max(dt::date) AS recency
-- ■ BigQuery의 경우 date_diff 함수 사용하기
-- , date_diff(CURRENT_DATE, date(timestamp(MAX(dt))), day) AS recency
--■ Hive, SparkSQL의 경우 datediff 함수 사용하기
-- , datediff(CURRENT_DATE(), to_date(MAX(dt))) AS recency
, count(dt) AS frequency
, sum(amount) AS monetary
FROM
purchase_log
GROUP BY
user_id
)
SELECT *
FROM
user_rfm

code 11-20. 사용자들의 RFM 랭크를 계산하는 쿼리
RFM 분석은 3개의 지표를 각각 5개의 그룹으로 나누는 것이 일반적.

WITH
user_rfm AS (
WITH
purchase_log AS (
SELECT
user_id
, amount
-- 타임스탬프를 기반으로 날짜 추출하기
-- ■ PostgreSQL, Hive, Redshift, SparkSQL의 경우 substring으로 날짜 부분 추출하기
, substring(stamp, 1, 10) AS dt
-- ■ PostgreSQL, Hive, Redshift, SparkSQL의 경우 substr 사용하기
-- , substr(stamp, 1, 10) AS dt
FROM
action_log
WHERE
ACTION = 'purchase'
)
, user_rfm AS(
SELECT
user_id
, max(dt) AS recent_date
-- ■ PostgreSQL, Redshift의 경우 날짜 형식끼리 빼기 연산 가능
, current_date - max(dt::date) AS recency
-- ■ BigQuery의 경우 date_diff 함수 사용하기
-- , date_diff(CURRENT_DATE, date(timestamp(MAX(dt))), day) AS recency
--■ Hive, SparkSQL의 경우 datediff 함수 사용하기
-- , datediff(CURRENT_DATE(), to_date(MAX(dt))) AS recency
, count(dt) AS frequency
, sum(amount) AS monetary
FROM
purchase_log
GROUP BY
user_id
)
SELECT *
FROM
user_rfm
user_id
)
, user_rfm_rank AS (
SELECT
user_id
, recent_date
, recency
, frequency
, monetary
, CASE
WHEN recency < 14 THEN 5
WHEN recency < 28 THEN 4
WHEN recency < 60 THEN 3
WHEN recency < 90 THEN 2
ELSE 1
END AS r
, CASE
WHEN 20 <= frequency THEN 5
WHEN 10 <= frequency THEN 4
WHEN 5 <= frequency THEN 3
WHEN 2 <= frequency THEN 2
WHEN 1 = frequency THEN 1
END AS f
, CASE
WHEN 300000 <= monetary THEN 5
WHEN 100000 <= monetary THEN 4
WHEN 30000 <= monetary THEN 3
WHEN 5000 <= monetary THEN 2
ELSE 1
END AS m
FROM
user_rfm
)
SELECT *
FROM
user_rfm_rank
728x90
'IT > SQL' 카테고리의 다른 글
| [데이터 분석을 위한 SQL 레시피] 5장 12강 시계열에 따른 사용자 전체의 상태 변화 찾기_part2(p.275~p.302) (0) | 2023.06.17 |
|---|---|
| [데이터 분석을 위한 SQL 레시피] 5장 12강 시계열에 따른 사용자 전체의 상태 변화 찾기_part1(p.233~p.275) (0) | 2023.06.17 |
| [데이터 분석을 위한 SQL 레시피] 4장 9강, 10강 (0) | 2023.06.17 |
| [해커랭크] Ollivander's Inventory (0) | 2023.04.08 |
| [해커랭크] Top Competitors (0) | 2023.03.31 |
Contents
소중한 공감 감사합니다