[에이블스쿨 8주차] 딥러닝1(딥러닝의 개념)

📝지난 수업을 정리해 봅시다~
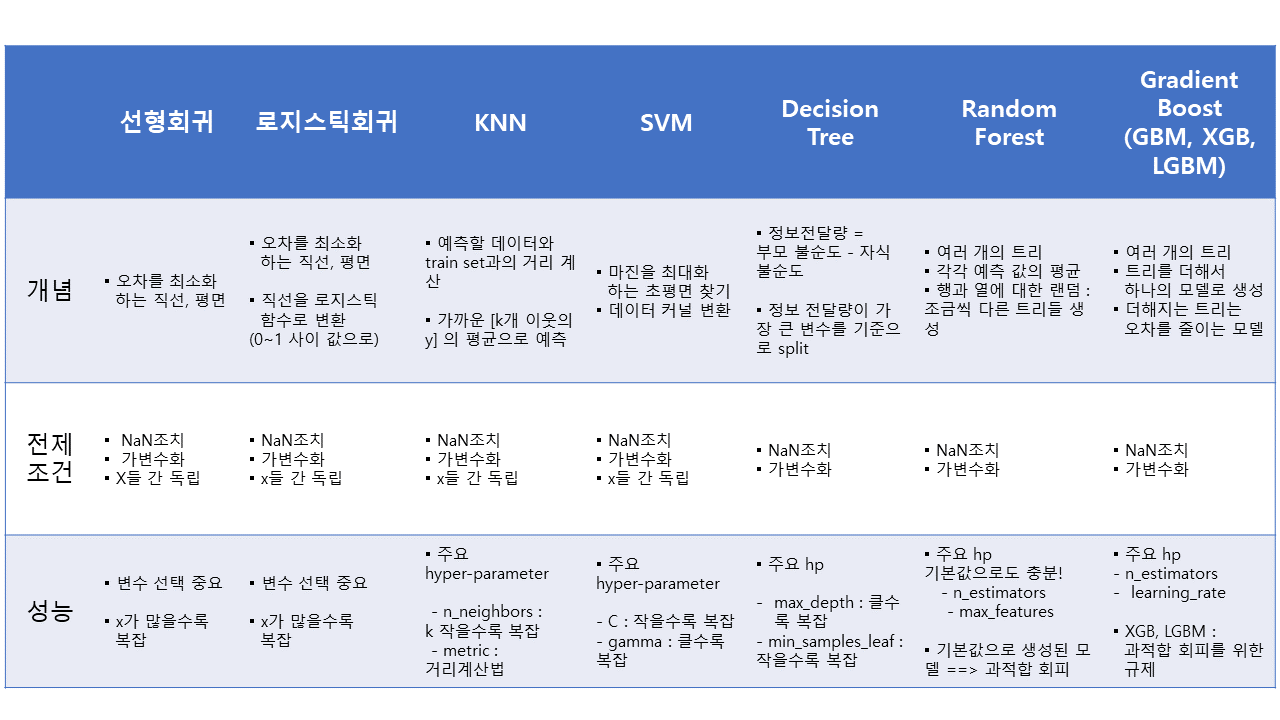
⭐알고리즘 한판 정리
모델 : 데이터로부터 패턴을 찾는 것
모델링 : 오차(train srror)가 적은 모델을 만드는 것
모델 튜닝 : validation error를 최소화하는 모델 선정
모델의 성능
# 오차의 제곱의 평균
# squared=False 를 하면 RMSE
print(f'RMSE : {mean_squared_error(y_val, pred, squared=False)}')
# 오차의 절댓값의 평균
print(f'MAE : {mean_absolute_error(y_val, pred)}')
딥러닝
딥러닝과 머신러닝의 차이
▪ 인공지능> 머신러닝 > 딥러닝 (인공지능이 가장 넓은 개념)
▪ 특성 추출(전처리) + 분류를 컴퓨터가 처리
: 머신러닝은 특성 추출을 인간이 처리 ← 개인의 의견이 개입됨(ex. 햇빛이 밝다, 어둡다)

| 구분 | 머신 러닝(범용적) | 딥러닝 |
| 동작 원리 | 입력 데이터에 알고리즘을 적용하여 예측을 수행한다. | 정보를 전달하는 신경망을 사용하여 데이터 특징 및 관계를 해석한다. |
| 재사용 | 입력 데이터를 분석하기 위해 다양한 알고리즘을 사용하며, 동일한 유형의 데이터 분석을 위해 재사용은 불가능하다. | 구현된 알고리즘은 동일한 유형의 데이터를 분석하는 데 사용된다. |
| 데이터 | 일반적으로 수천 개의 데이터가 필요하다. | 수백만 개 이상의 데이터가 필요하다. |
| 훈련시간 | 단시간 | 장시간 |
| 결과 | 일반적으로 점수 또는 분류 등 숫자 값 | 출력은 점수, 텍스트, 소리 등 어떤 것이든 가능 |
[출처 : 딥러닝 텐서플로 교과서]
- 스케일링이 필수
- 모델 선언대신 모델구조, 컴파일이 있음
- 학습 후 학습곡선을 시각적으로 확인
딥러닝 개념 이해
가중치
w = 가중치
최적의 가중치를 찾기 위해
- 조금씩 가중치(weight)를 조정하며
- 오차가 줄어드는지 확인한다.
- 언제까지? 지정한 횟수만큼 or 더 이상 오차가 줄어들지 않을 때까지
학습절차
node : 어떤 정보
학습 과정 동안 인공 신경망으로서 예시 데이터에서 얻은 일반적인 규칙을 독립적으로 구축(훈련)
model.fit(x_train, y_train) 하는 순간!
- 가중치에 (초기) 값을 할당한다. [초기값은 랜덤으로 지정 → 돌릴 때마다 그래프가 다르게 나옴]
- (예측) 결과를 뽑는다.
- 오차를 계산한다.
- 오차를 줄이는 방향으로 가중치를 조정
- 다시 1단계로 올라가 반복한다.
epochs = ep == 반복 횟수 == 학습곡선의 x축
learning_rate=lr == 학습률 == (오차를) 학습하는 정도
Regression
- 딥러닝 전처리 : 스케일링
- 네트워크 ↔ 모델구조
- compile
- 학습곡선
- 회귀모델 평가 Review
⭐딥러닝은 스케일링을 필요로 합니다.
# 스케일러 선언
scaler = MinMaxScaler()
# train 셋으로 fitting & 적용
x_train = scaler.fit_transform(x_train)
# validation 셋은 적용만!
x_val = scaler.transform(x_val)
딥러닝 구조
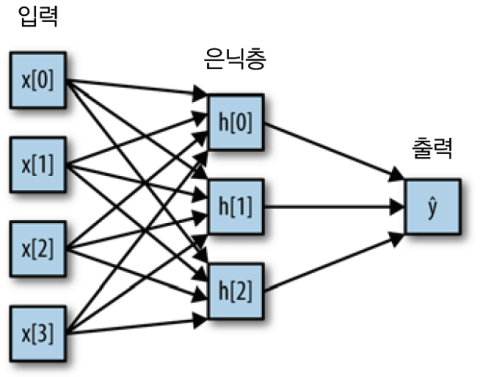

- Hidden Layer(은닉층)이 없으면 단층-퍼셉트론, Hidden Layer가 존재하면 다층 퍼셉트론(Multi-layer Perceptron, MLP)
- 퍼셉트론이란? 입력->연산->출력 시스템
Process
①각 단계(task)는
- 이전 단계의 Output을 Input으로 받아
- 처리한 후
- 다음 단계로 전달
②공통의 목표를 달성하기 위해서 동작
Dense
# 메모리 정리
clear_session()
# Sequential 타입
model = Sequential([Dense(1), (input_shape=(nfeaturs, ))] ) # 1은 Output, nfeaturs는 Input
# 모델요약
model.sDense(❔)
노드를 몇 개를 출력할 것인가
input_shape(❔, )
input, 분석단위
🤔왜 (nfeatures, ) 공백이 오는 건가요
⭐1차원의 shape (방향이 없습니다❗)
# 1차원 array
a = np.array([1, 2, 3])
a.shape
# 결과
(3, )
Compile
선언된 모델에 대해 몇 가지 설정을 한 후, 컴퓨터가 이해할 수 있는 형태로 변환하는 작업
model.compile(
optimizer = Adam(learning_rate = 0.1)
, loss='mse')
loss function(오차함수)
- 오차 계산을 무엇으로 할지 결정
- 회귀모델은 보통 mse로 오차 계산
optimiser
- 오차를 줄이는(최소화하도록) 가중치를 조절하는 역할
- optimizer = 'adam’ : learning_rate 기본값 = 0.001
- optimizer = Adam(lr = 0.1) : 옵션 값 조정 가능
learning_rate
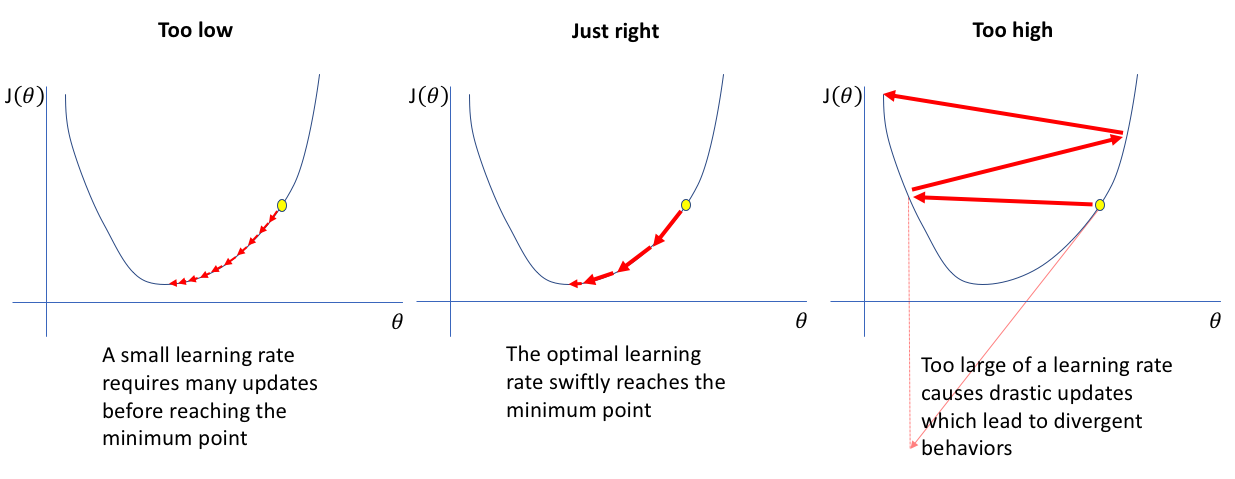
학습
✅epochs 반복 횟수
- 가중치 조정 반복 횟수
- 전체 데이터를 몇 번 학습할 것인지 정해 줌
✅validation_split = 0.2
- train 데이터에서 20%를 검증 셋으로 분리
✅. history
- train 데이터에서 20%를 검증 셋으로 분리
history = model.fit(x_train, y_train,
epochs = 20, validation_split=0.2).history
# loss 와 val_loss를 보면 오차가 줄어드는 걸 볼 수 있다.
# .history 는 loss, val_loss 의 값을 저장하고 있다.
입력이 여러 개일 경우 리스트로 만들어 줌.