AIVLE School DX 3기
[에이블스쿨 6주차] 머신러닝5 + 코딩마스터즈 마감
- -
728x90
반응형

1교시부터 시작된 어려운 개념.....
Linear Regression
변수가 많을수록 복잡해진다
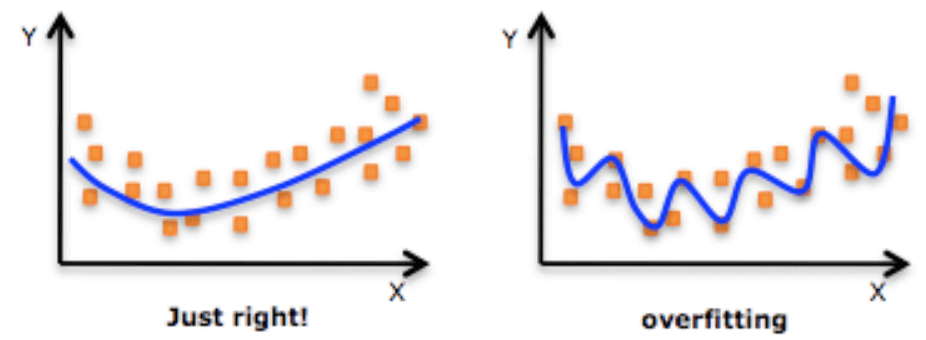
과적합 : 학습성능에 비해 평가성능이 떨어지는 것
[과적합 해결]
Ridge : 가중치를 눌러준다 (규제 강도 alpha)
Lasso : 작은 가중치를 제거한다
ElasticNet : Ridge와 Lasso를 둘 다 사용한다
🤔가중치를 눌러주는 게 어떻게 과적합을 방지할 수 있나요?
[다중공선성 줄이기]
VIF: 10보다 크면 독립변수는 다중공산성이 있다.(R2가 커질수록 VIF가 커진다.)
KNN
k값이 클수록 단순하다.
(학습데이터의 평균에 가까워진다.)

SVM(Support Vector Machine)
결정 경계선(Decision Boundary)을 찾는 알고리즘
커널종류(Linear, Ploy, RBF)를 지정해 곡선의 그래프도 SVM을 그릴 수 있다
| 용어 | 설명 |
| 결정 경계(Decision Boundary) | 서로 다른 분륫값을 결정하는 경계 |
| 벡터(Vector) | 2차원 공간 상에서 나타난 데이터 포인트 |
| 서포트 벡터(Support Vector) | 결정 경계선과 가장 가까운 데이터 포인트 |
| 마진(Margin) | 서포트 벡터와 결정 경계 사이의 거리 • 마진을 최대로 하는 결정 경계를 찾는 것이 SVM의 목표 • 마진이 클수록 새로운 데이터에 대해 안정적으로 분류할 가능성이 높음 |
COST의 의미
model = SVC(kernel='linaer', c=10)
cost값이 커질수록 결정경계가 정확해지지만 마진이 줄어든다 ← 과대적합
gamma
모델이 생성하는 경계가 복잡해지는 정도
🤔회귀에서도 사용이 가능한가요?
네!
분류는 SVC / 회귀는 SVR
SVR(kernel='rbf', C=cost, epsilon=0.5, gamma=1)
eplsilon을 사용해서 사용가능합니다ㅏ.
❗문제점
- 평가를 해보기 전에 성능을 예측할 수 없음
- 학습용 데이터의 일부를 검증용 데이터로 사용해서 해결
😥그럼에도 생기는 문제점
무작위 추출 후 여러번 검증을 하면
- for문을 돌리면 너무 번거로움
- 랜덤으로 선택하면 계획성이 없어 보임
K-Fold Cross Validation
K개의 Fold를 만들어서 교차검증하는 방법
모든 데이터는 한 번은 평가용, k-1번은 학습용으로 사용됨(k는 2 이상)
⭐train data만 나눕니다!!!
| 장점 | 평가에 사용되는 데이터의 편향을 막을 수 있음 |
| 단점 | 반복 횟수가 많아서 모델 학습과 평가에 많은 시간이 소요됨 |
# 1단계: 불러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
# 2단계: 선언하기
model = DecisionTreeClassifier(max_depth=3)
# 3단계: 검증하기
cv_result = cross_val_score(model, x_train, y_train, cv=10)
# 확인
print(cv_result)
print(cv_result.mean())cross_val_score() 함수는 scoring 매개변수에 원하는 평가 지표를 지정할 수 있습니다.
분류 문제일 경우 기본은 정확도를 의미하는 ‘accuracy’입니다.
cross_val_score(SVC(gamma='auto'), X_train, y_train, scoring='accuracy' cv=3)
KNN과 SVM은 정규화를 따로 해줘야 한다.
# 모듈 불러오기
from sklearn.preprocessing import MinMaxScaler
# 정규화
scaler = MinMaxScaler()
scaler.fit(x_train)
x_train_s = scaler.transform(x_train)
x_test_s = scaler.transform(x_test)
Linear Regression코드
# 불러오기
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
# 선언하기
model = DecisionTreeClassifier(random_state=1)
# 검증하기
cv_score = cross_val_score(model, x_train, y_train, cv=10)
# 확인
print(cv_score)
print('평균:', cv_score.mean())
print('표준편차:', cv_score.std())
# 성능정보 수집
result = {}
result['Decision Tree'] = cv_score.mean()
헷갈려
| import | scorint | |
| 분류 | Classifier | accuracy |
| 회귀 | Regressor | r2 |
cv는 큰 값만 좋아함
MSE가 10과 20이 있다면 10이 성능이 더 좋음
하지만, cv는 큰 숫자를 찾음
→ 숫자에 -를 붙여서 해결
→ -10과 -20 중 -10을 선택
참고 사이트 : https://tensorflow.blog/tag/cross_val_score/
🤖코딩마스터즈 마감

1차 코딩마스터즈가 마감이 되었습니다!
코딩마스터즈가 끝이 났어도 다른 에이블러분들이 코드를 어떻게 짰는지 볼 수 있게 자가학습 기간을 열어주십니다.
뿐만 아니라 DX여도 더 많은 코딩테스트 기회를 주기 위해 에이블에서는 코딩테스트도 따로 진행하고 있으니 한번 도전해봐야겠어요😤
728x90
'AIVLE School DX 3기' 카테고리의 다른 글
| [에이블스쿨 7주차] 머신러닝7(앙상블, 클래스불균형) (0) | 2023.03.14 |
|---|---|
| [에이블스쿨 7주차] 머신러닝6 (0) | 2023.03.13 |
| [에이블스쿨 6주차] 머신러닝4 (0) | 2023.03.09 |
| [에이블스쿨 6주차] 머신러닝3 (0) | 2023.03.08 |
| [에이블스쿨 6주차] 머신러닝2 (0) | 2023.03.07 |
Contents
소중한 공감 감사합니다